


| 论坛帮助 |
| 社区圈子 |
| 日历事件 |
 2022-11-01, 00:52
2022-11-01, 00:52
|
#1 | ||
|
|||
|
正式会员
等级: 三袋长老
 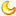 
|
i1以外的色彩量测仪器陆续在市场上出现,数据一致性这个问题避免不了! 这个问题衍生出几个工作面向需要去处理。 一、什么样的差异是堪用的?1个de00?两个de00? 我的看法:对要拿认证的厂,会要求到1个de00。资料上,Techkon SpectroDens 与 Xrite eXact 也是有1个de00的差距。 还有更多更多的厂、还没有建立起数据观念的厂,一些较低门坎的、两个de00的敲门砖,我还是认可的。这些低门坎的设备,还是可以帮着带到相当的位置。 以上图中 Epson sd-10 、 CR30 跟 i1 的差距大约都是两个de00;倒是 sd10 与 cr30 的差距还小一些,我的数据落在1.38 de00。 二、经由这些仪器将色彩解译为数字,一旦是数字,我们就可以透过一些数学(统计学)程序来优化这些数字,让仪器之间呈现的数值可以更接近。不管低阶高阶,对我来说,是有必要去找一个工作程序,让两个仪器的数字接近。 上次做过一次以纸白的光谱差别作为修正基础,有取得一些改善成果,但多测试些样本的时候,发现有的颜色的色差反而变大,这样的结果还是不够安全。就像某个药品广告说的:先求不伤身体,再来讲求疗效。同样的,我必须先找一个比较保守的方法,至少色差不能变大,再来讲究数据差的缩小。 这次经由以前的工作伙伴蔡同学处取得python Machine Learning 的样版程序,想着这个对我 data approaching 这个题目应该有幚助。 再去多了解一些,看来就是很多统计学的函式库,主要是在调用上显得方便零活许多。内容很多,需要一些时间去消化理解。这次先试试 Multiple Regression 看看能有什么成果。 首先,要怎么喂数据就是一门学问:要多少样本数?色彩样本的分布情况?样本的参考点要设多少个?怎么设? 一方面要增加精度、一方面又要让操作尽量精简;各种方面的考虑需要不断的Trail and error去找到最佳的组合。 Fig. 这次用了16个样本来学习。 Fig. 参考点取4个地方,分别是 460nm, 520nm, 630nm 及光谱反应总和(weight)。 依程序回测了三个样本,大概就从2个de00拉到1个de00左右,算是有効的运作。 Fig. 样本一,de00由 2.42降到1.42。样本二,de00由 1.85降到1.18。样本三,de00由 2.16降到1.27。 这次只是Machine learning 在 Data Approaching 的一个开端,各种machine learning 的运用还需要去更深入了解,样本的取用逻辑及数据的喂法都还在尝试及学习。 仪器间的数据迫近在我这边会是一个长期的题目,随着样本收集方式的改进与对machine learning 能力的理解与运用,期待的是精度再提升、操作方式更精简。 计划目标是随时都能迫近到一个de00,会是以云端平台的方式提供服务;利用平台的大量收据来继续精进machine learning 的结果。这当中大量仪器的数据与机器学习之间的串接,还需要大量IT能力的支持。 先画个饼,能实现到什么程度我也不知道,总之,是该开始动起来了。 |
||

|
|
2022-12-08, 22:48
|
只看该作者 #3 | ||
|
|||
|
正式会员
等级: 一袋长老
|

分享两个想法: 1. 可以加入BCRA tile sets,虽然数量并不多,但是毕竟样品稳定而且行业应用普遍。不管用什么数学模型,train data直接影响结果。 2. 本人尚未涉及data approaching,但之前试用Scikit regression来做一些油墨的课题,也是不错的复查的工具。 加油。 |
||
|
|




